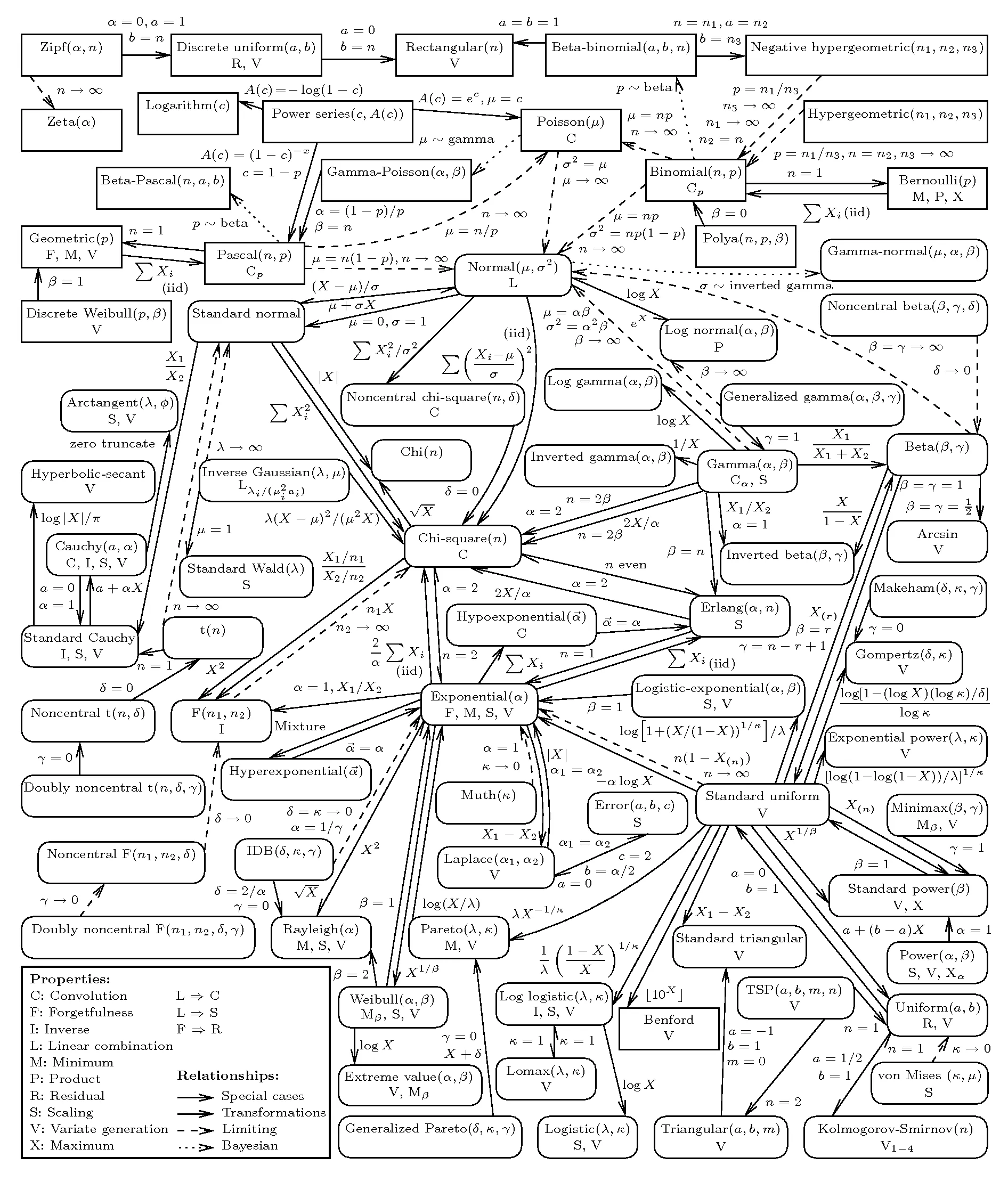
Distributions
Note that we are actually modeling the conditional distribution of the response variable (so Y|X, not the marginal Y). Observing skewness on the marginal target distribution does not necessarily mean that the conditional distribution is skewed, nor should we apply log transformation to the target variable to make it normal. For example, a Y|X follows normal distribution while X follows Poisson distribution would lead to a right skew marginal distribution of Y. However, we would never observe the full picture of the conditional distribution. So the choice of the distribution to model, or to form a loss function, often comes from our imaginations, business thoughts, statistical intuitions, and mathematical tractability. ref
Popular choice of modeling
- The heights of a population are normally distributed.
- The sampling distribution of the sample mean is normally distributed if the sample size is large enough, even if the population is not normally distributed (CLT).
- The outcome of a coin flip is Bernoulli distributed.
- The number of heads in n coin flips is binomial distributed.
- The number of successes in n events without replacement is hypergeometric distributed.
- The number of events in a fixed interval of time is Poisson distributed. It assumes the conditional variance is the same as the conditional mean.
- The time between events in a Poisson process is exponentially distributed.
- The number of failures before the r-th success in a sequence of Bernoulli trials is negative binomial distributed. It allows overdispersion, that is, the conditional variance is greater than the conditional mean, even it is substantially higher.
- The number of trials until the first success in a sequence of Bernoulli trials is geometric distributed.
- [Beta geometric distribution] is a compound distribution that is generalization of the geometric distribution. The beta geometric distribution extends geometric distribution by allowing flexibility in how probabilities change from one trial to another. Which is good for churn prediction.
- Gamma distribution is the continuous analog of the negative binomial distribution. ref.ref2 when to use gamma glms
- Log gamma distribution is left skewed, i.e. longer tail at the left. It is great to model such kind of data. discussion on gamma vs lognormal
- Any continuous proportion data without 0s and 1s can be modeled with beta distribution. It can be augmented by zero-inflated / one-inflated model to include 0s and 1s. example ref
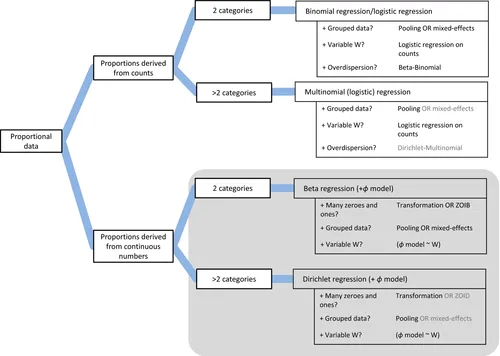
- Dirichlet distribution is a multivariate generalization of the beta distribution. It is used to model the distribution of proportions. It is different from using multiple beta distributions in that it consider covariances between the beta variables, i.e. those random variables are no longer independent. It is the conjugate prior of categorical distribution and multinomial distribution, which are the generalization of Bernoulli distribution and binomial distribution respectively. blog usage distribution explorer
- Asymmetric Laplace distribution is great for quantile regression. It can be parametrized by quantile as symmetry parameter, mean as location parameter, and standard deviation as scale parameter . Although drawing quantiles of posterior mean is okay, the shape of curves is essentially the same just shifted up and down, i.e. for the Gaussian family the variability always stays the same. However, using asymmetric Laplace distribution, it allows the model to account for the increased variability in response as the covariates increases. example paper
- Zero-sum-normal distribution is a multivariate normal distribution with zero mean and covariance matrix, where . It is useful to capture the relative difference across some axes, e.g. for modeling seasonality. doc
- Tweedie distribution is good to model zero-inflated data, e.g. insurance total loss It assume that the probability of an exact zero is related to the expected value of the process. If the expected value is low, then zeros will be more common. If the expected value is high, then zeros will be less common. This relationship can be tuned somewhat by choosing the index of the Tweedie model but, if the relationship doesn’t hold as expected, then a more complex ZI model may be required. ref
- Note that Tweedie regression is actually Poisson-Gamma regression, where the Poisson distribution is used to model the frequency and the Gamma distribution is used to model the severity, i.e. the monetary value per claim. ref
Check out the Distribution Explorer#Story of each distribution for more information.
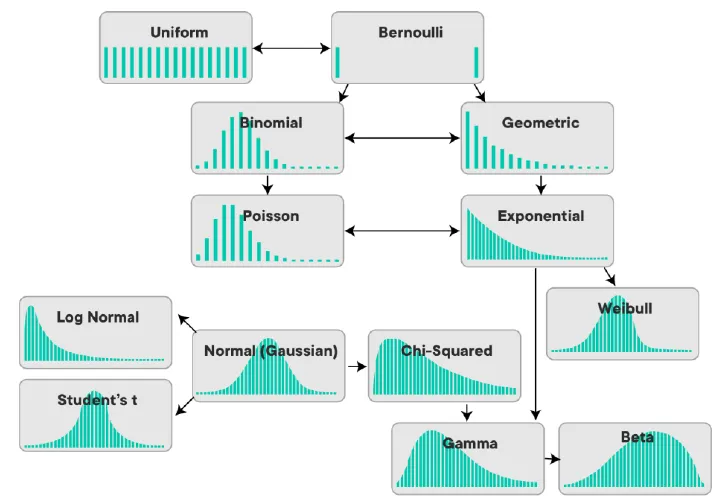
Distribution transformation
- Sum of two independent normal random variables is a normal random variable.
- There are other distributions that have this property, such as the binomial, Cauchy, Poisson, gamma, beta, and Student’s t distributions.
- Sum of n independent exponential random variables is a gamma random variable with shape parameter n.
- The Gamma distribution is the continuous analog of the Negative Binomial distribution.
- Bernoulli distribution is a special case of the binomial distribution with n=1.
- Sum of n Bernoulli random variables is a binomial random variable.
- Beta distribution is a special case of the Dirichlet distribution.
- Cauchy distribution distribution is a special case of the Student-t distribution in which .
- Normal distribution is a special case of the Student’s t distribution.
- A standard normal deviate is a random sample from the standard normal distribution. The Chi Square distribution is the distribution of the sum of squared standard normal deviates. The degrees of freedom of the distribution is equal to the number of standard normal deviates being summed.
Check out the Distribution Explorer#Related distributions of each distribution for more information.
Loss distributions
It can be applied to build a loss function that fits the business problem. Note that whenever developing custom loss distributions that are not implemented by the libraries, deviance objective function, gradients, and Hessians should be implemented and provided to the library. How it is done is directly related to deriving loss function in GLM. Following are some industries that use specific distributions as a loss function:
- Doordash - Using Gamma Distribution to Improve Long-Tail Event Predictions
- Improving ETA Prediction Accuracy for Long-tail Events
- Note that the team modeled the entire delivery time instead of breaking it up into sub-components because delivery estimates are complex to predict considering variance in preparation time, dasher assignment, traffic, and difficulty in finding customer’s doors. If most of the sub-components could not be modeled correctly, the errors induced would be accumulated to yield much poor overall estimates
- Tweedie distribution as a loss function to estimate forecasts of the unit sales of various products sold in the USA by Walmart.
And the following are the resources detailing the theory behind:
- StackExhange | Loss functions for specific probability distribtuions?
- Loss Distributions
- Piecewise linear approximations of the standard normal first order loss function
- Piecewise linearisation of the first order loss function for families of arbitrarily distributed random variables
Acknowledgements
- Univariate Distribution Relationships Graph
- Distribution Explorer
- Statistics in Marketing - Continuous Probability Distributions
- How to Learn Probability Distributions
Best Graph for Distributions